What is the difference between DBSCAN and OPTICS?
By Gabriel Cooper
What is the difference between DBSCAN and OPTICS?
OPTICS. OPTICS works like an extension of DBSCAN. The only difference is that it does not assign cluster memberships but stores the order in which the points are processed. So for each object stores: Core distance and Reachability distance.
Is OPTICS faster than DBSCAN?
OPTICS comes at a cost compared to DBSCAN. Largely because of the priority heap, but also as the nearest neighbor queries are more complicated than the radius queries of DBSCAN. So it will be slower, but you no longer need to set the parameter epsilon.
What is DBSCAN clustering used for?
DBSCAN is a clustering method that is used in machine learning to separate clusters of high density from clusters of low density.
What are the 2 major components of DBSCAN clustering?
DBSCAN requires only two parameters: epsilon and minPoints. Epsilon is the radius of the circle to be created around each data point to check the density and minPoints is the minimum number of data points required inside that circle for that data point to be classified as a Core point.
What are the advantages of Dbscan algorithm what are its limitations?
Advantages
- DBSCAN does not require one to specify the number of clusters in the data a priori, as opposed to k-means.
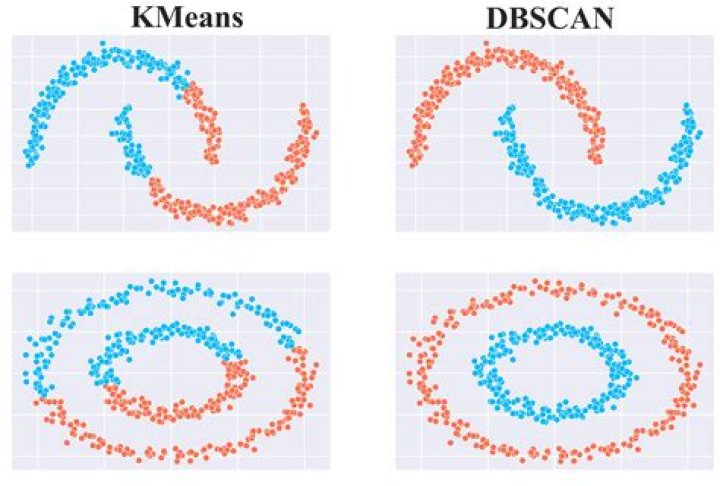
- DBSCAN can find arbitrarily-shaped clusters.
- DBSCAN has a notion of noise, and is robust to outliers.
In which case cases you will use Dbscan?
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is a popular learning method utilized in model building and machine learning algorithms. This is a clustering method that is used in machine learning to separate clusters of high density from clusters of low density.
Why is Kmeans better than DBSCAN?
Advantages. DBSCAN does not require one to specify the number of clusters in the data a priori, as opposed to k-means. DBSCAN can find arbitrarily-shaped clusters. It can even find a cluster completely surrounded by (but not connected to) a different cluster.
What is the basic principle of DBSCAN clustering?
The principle of DBSCAN is to find the neighborhoods of data points exceeds certain density threshold. The density threshold is defined by two parameters: the radius of the neighborhood (eps) and the minimum number of neighbors/data points (minPts) within the radius of the neighborhood.
How is DBSCAN implemented?
Implementing DBSCAN algorithm using Sklearn
- Step 1: Importing the required libraries.
- Step 2: Loading the data.
- Step 3: Preprocessing the data.
- Step 4: Reducing the dimensionality of the data to make it visualizable.
- Step 5: Building the clustering model.
- Step 6: Visualizing the clustering.
What are the disadvantages of DBSCAN?
Disadvantages
- DBSCAN algorithm fails in case of varying density clusters.
- Fails in case of neck type of dataset.
- Does not work well in case of high dimensional data.
What is density-based clustering used for?
The Density-based Clustering tool works by detecting areas where points are concentrated and where they are separated by areas that are empty or sparse. Points that are not part of a cluster are labeled as noise.