What is Max entropy model?
By Mia Lopez
What is Max entropy model?
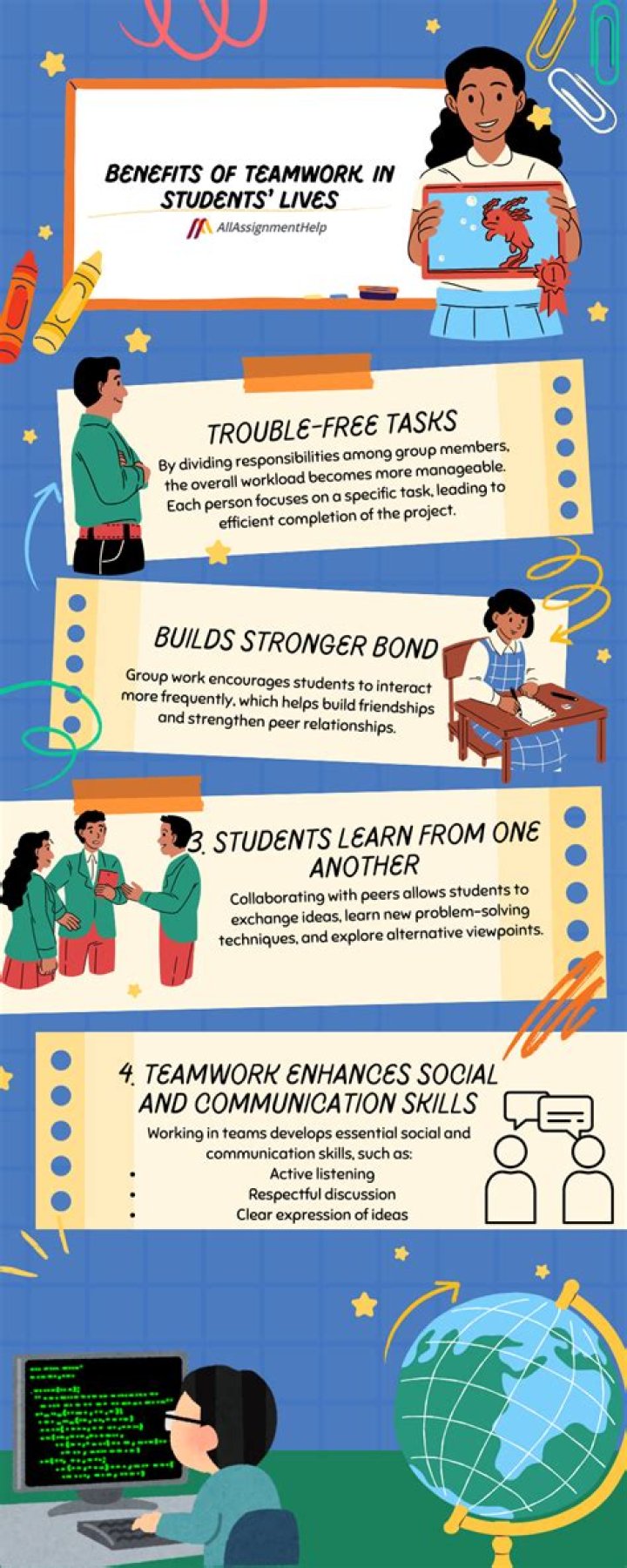
The maximum entropy principle (MaxEnt) states that the most appropriate distribution to model a given set of data is the one with highest entropy among all those that satisfy the constrains of our prior knowledge. Usually, these constrains are given as equations regarding moments of the desired distribution.
How is maximum entropy different from HMM?
Maximum entropy models do not assume independence between features, but generative observation models used in HMMs do. Therefore, MEMMs allow the user to specify many correlated, but informative features. In HMMs and CRFs, one needs to use some version of the forward–backward algorithm as an inner loop in training.
What is memm in NLP?
NLP: Text Segmentation Using Maximum Entropy Markov Model (MEMM) MEMM is a combination of HMM with the Maximum Entropy (MaxEnt) model. MaxEnt model is a type of log-linear model which we will discuss next.
Why is memm better than HMM?
HMM directly models the transition probability and the phenotype probability, and calculates the probability of co-occurrence. MEMM establishes the probability of co-occurrence based on the transition probability and the phenotype probability.
Is maximum entropy possible?
He has found that the maximum entropy distribution is the most probable of all “fair” random distributions, in the limit as the probability levels go from discrete to continuous.
What happens when entropy is maximum?
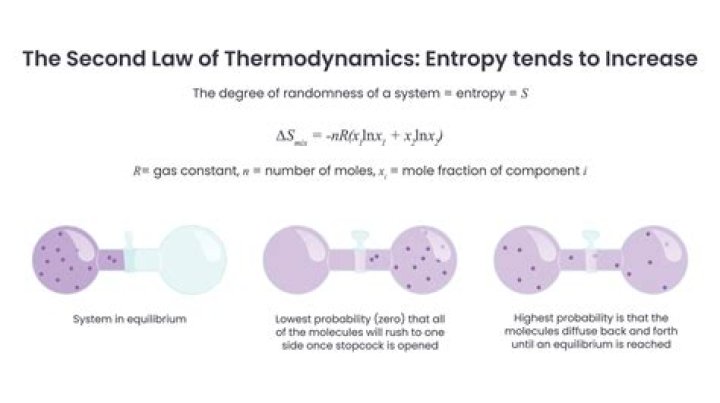
When the entropy reaches the maximum value, the heat death of the universe happens. Heat death happens when the universe has reached equilibrium due to maximum entropy. This will happen when all the energy from the hot source moves to the cold source and everything in the universe will be of the same temperature.
Is maximum entropy same as logistic regression?
3 Answers. This is exactly the same model. NLP society prefers the name Maximum Entropy and uses the sparse formulation which allows to compute everything without direct projection to the R^n space (as it is common for NLP to have huge amount of features and very sparse vectors).
What is the major difference between CRF Conditional Random Field and HMM hidden Markov model ?
Discussion Forum
| Que. | What is the major difference between CRF (Conditional Random Field) and HMM (Hidden Markov Model)? |
|---|---|
| b. | Both CRF and HMM are Generative model |
| c. | CRF is Generative whereas HMM is Discriminative model |
| d. | Both CRF and HMM are Discriminative mode |
| Answer:CRF is Generative whereas HMM is Discriminative model |
Is memm good for MCAT?
I found Memm to be very helpful in studying for my MCAT. It provides all the necessary information without the unnecessary fluff you’d find with other test prep material. Its spacing software ensures that you’ll remember everything you need to know on test day.
What is an example of increasing entropy?
Dissolving salt in water is another example of increasing entropy; the salt begins as fixed crystals, and the water splits away the sodium and chlorine atoms in the salt into separate ions, moving freely with water molecules. The ice turns to water, and its molecules agitate like popcorn in a popper.
What is the difference between maximum entropy Markov model and HMM?
The Maximum Entropy Markov Model (MEMM) has dependencies between each state and the full observation sequence explicitly. This is more expressive than HMMs. In the HMM model, we saw that it uses two probabilities matrice (state transition and emission probability).
What is maximum entropy in machine learning?
Maximum entropy is a framework for estimating probabil- ity distributions from data. It is based on the principle that the best model for the data is the one that is consistent with certain constraints derivedfromthe trainingdata, but other- wise makes the fewest possible assumptions.
What is the difference between maximum entropy model and logistic regression?
Maximum Entropy Model Similar to logistic regression, the maximum entropy (MaxEnt) model is also a type of log-linear model. The MaxEnt model is more general than logistic regression. It handles multinomial distribution where logistic regression is for binary classification.
What is the difference between naive Bayes and hidden Markov model?
In an earlier Hidden Markov Model (HMM) approach, we see that it can capture dependencies between each state better than Naive Bayes (NB). NB assumes input values are conditionally independent, while HMM captures dependencies between each state and only its corresponding feature.